
Acknowledgements
The Local Government Association (LGA) would like to thank Shared Intelligence (Si) for conducting this work. We would also like to thank all the local authority participants who took part in the action learning sets, and the advisory board members who gave comments on the guide.
Disclaimer
The views in this report are the authors’ own and do not necessarily reflect those of the LGA.
Introduction
The LGA commissioned Si in December 2019 to develop a guide to using predictive analytics. The use of predictive analytics in local government is still at an early stage, although it is becoming more common. While there are some sophisticated examples of predictive analytics being used across a range of local public services, much of the sector is just starting to consider the opportunities, and risks, of this type of technology.
A council might want to use predictive analytics to improve outcomes and manage their increasingly scarce resources better, through automation, earlier intervention and better prediction and targeting. However, how councils do this is a developing art. This report aims to provide a guide for councils about predictive analytics and how they might use this technology.
To develop this guide, Si and the LGA gathered contributions from councils where predictive analytics are already being used and from national organisations with policy and technical expertise. This process included:
- Two action learning sets (which each met three times) comprised of staff from council data teams using or developing predictive analytics approaches.
- Co-opting the skills of a senior data scientist from the commercial sector who offered a comparative perspective.
- Desk review of formal and grey literature on the use of predictive analytics.
- Identifying case studies from public service contexts both nationally and internationally.
- In-depth interviews to understand the issues faced by local government in using predictive analytics, and to develop case studies.
- Testing with an advisory group formed of individuals, both within and external to local government, who have specialist research and policy knowledge of predictive analytics and other forms of data science.
What do we mean by ‘predictive analytics’?
Defining predictive analytics can be difficult; the term is not always used consistently and overlaps with other fields of data science and technology. For the purposes of this guide we define our use of the term in the box below.
Predictive analytics can usefully be employed in situations where there is a large data set of historical observations and where decision-making is difficult, time-consuming, or outcome-critical; or where human operators can give a computer program a closed question to answer such as asking the software to sort cases into different categories, or provide a risk score for each case.
A useful source of further reading on definitions of predictive analytics and artificial intelligence (AI) technologies in the context of public services is the Department for Digital, Culture, Media and Sport (DCMS) guidance on understanding Artificial Intelligence.
Where are councils now in the use of predictive analytics?
The use of predictive analytics in local government remains at an early stage, particularly when compared with the private sector. The private sector has seen a widespread and well-established application of predictive analytics over the past two decades in areas including credit-scoring, marketing, telecoms, energy demand, travel and logistics planning, social-networking and retail, where it is used to better target customers and forecast. What we have found is that in local public services predictive analytics is generally small scale, at an early or exploratory stage, and confined to narrow categories (typically areas such as troubled families and child protection, personal social care, housing repairs, credit control, and inquiry handling). This view is reinforced by a comprehensive review of data science approaches in local government produced by the Oxford Internet Institute in 2019. The Oxford Internet Institute report also highlights the familiar paradox brought about by a decade of extreme budget pressure:
‘Whilst in theory the context of austerity provides stimulus for innovation, in practice the dramatic reductions in budgets have meant that back-office analysts […] are almost exclusively focussed on statutory reporting, with hardly any possibility of engaging in new work.’
Nonetheless, the potential for this type of technology goes far beyond the current range and extent of uses and has potential to be genuinely transformational for frontline community services. We have seen a small number of genuinely ground-breaking applications which suggest this type of technology is on the brink of real take-off. For this reason, it has generated significant interest in recent years both in terms of services which are routine and services which are safety critical. In 2016, when the use of predictive analytics in councils was at an even earlier stage, the Nesta report Datavores of Local Government singled out predictive analytics as having potential in children’s services. Since then, uses of predictive analytics have been tested in many other areas. Typically, these are cases with potential for improving accuracy, outcomes, or gaining benefits from early intervention or identification of needs, which in turn reduces emergency interventions. While some councils are developing their own in-house systems and applications, many are purchasing third party systems which introduces a market dynamic into the pattern of development (for example, multiple authorities may adopt essentially the exact same product and associated processes).
At the same time, the amount of analysable data which councils collect and store has also grown exponentially as 'The Future of Predictive Analytics in Councils' by the University of Essex outlines. The idea that local government is holding ever more data can make it hard to distinguish between potential for progress and actual progress. This is one reason why we refer several times to ‘data maturity’ models such as the LGA’s Data Maturity Tool and the Social Sector Data Maturity Framework which enable organisations to benchmark their stage of development.
What are predictive analytics approaches being used for in local public services?
The adoption of predictive analytics varies considerably across councils and the following three case studies convey the range we have seen.
What factors affect the adoption of predictive analytics in local public services?
Our research in developing this guide identified a number of recurrent factors which influence the adoption of predictive analytics which can be seen in the following sections:
- corporate understanding of the nature of these technologies and the value they can add
- budget pressures, which mean service delivery is prioritised over service development that needs investment, such as predictive analytics
- fragmented approaches to data within organisations and data quality generally
- enabling factors for digital innovation such as the removal of firewalls or other restrictions which prevent data teams from accessing new software
- confidence around how to maintain and build public and community trust in data science
- availability of skilled analysts and/or means to acquire this expertise
- buy-in among frontline staff whose services could benefit from predictive analytics
- clear narratives which addresses public concerns over computer-based decision-making including around bias, replacing human jobs, safety, and ethics.
These factors are all interdependent: for example, if corporate understanding of the potential of predictive analytics is weak, it is harder to obtain funding for innovative investment, which in turn makes it harder to achieve the progress needed to build frontline staff buy in and a clear public narrative.
Broader concerns over computer-based decision making
The broader public concern about computer-based decision-making has clearly become a factor which affects decision-making within councils, and we heard this on multiple occasions from council data teams themselves. It creates an additional layer of cautiousness internally among senior officers and elected members. These concerns came to the fore during the COVID-19 crisis and the school exams algorithm episode of 2020, but reflect long-standing public caution about advanced technology and society. However, while the exams episode certainly fuelled public concern, it was not about computers becoming too clever but about algorithms getting things wrong.
Concern that powerful software will ‘replace’ human roles is still part of the wider narrative. So is concern that there are insufficient governance controls to prevent harms or undesirable uses. There are also broader worries about organisations holding the personal data upon which predictive analytics relies; for example, a recent survey by Onward found only 31 per cent of the public trust their council to use their data ethically. The same study argues that COVID-19 has exposed ‘the underdeveloped nature of the UK’s digital social contract’.
These issues are exacerbated by media attention which is often critical or sceptical of the use of predictive analytics by local government and which has tended only to highlight failures.
More recently, critics have focused on the risk of bias in computer-aided decision-making and the potential for social inequalities and prejudices to be exacerbated.
However, public opinion is not straightforward, and we should not assume there is a general public anxiety about computers making decisions. For example, the Information Commissioner’s Office’s (ICO) ‘Project ExplAIn’ found the public comfortable with computer-based decisions in certain areas of healthcare diagnosis and willing to accept decisions with no explanation, yet they were more cautious about uses in criminal justice and recruitment, where those questioned said they wanted an explanation of why a decision has been made by AI.
How can councils address issues of trust?
What we heard consistently as we developed this guide was that there are already well-grounded and carefully created frameworks which address issues of data-quality, application of predictive analytics, ethical considerations, governance, privacy, and trust.
But these need to be applied and decision-makers must be familiar with them and understand them in the same way they understand other important frameworks, for example, like safeguarding.
The currently available ‘essential reading’ in our view includes:
- the Government’s Data Ethics Framework and
- Addressing Trust in Public Sector Data Use from the Centre for Data Ethics which includes a framework for building trust with the public based on five questions about ‘value’, ‘security’, ‘accountability’, ‘transparency’, and ‘control’.
These documents themselves contain links to many other authoritative sources of guidance and are essential jumping off points for anyone working with data in public services. As advanced uses of data become more integral to the operations of councils, these frameworks will need to become as familiar among decision-makers and accountable individuals in local government as frameworks around equalities and safeguarding.
Benefits of predictive analytics
The use of predictive analytics in the private sector in areas such as credit scoring has revolutionised personal finance through statistical modelling of the characteristics of an individual. It ‘allows one to distinguish between ‘good’ and ‘bad’ loans and give an estimate of the probability of default as this credit scoring report by Deloitte shows.’ Those who work closely with predictive analytics in the public sector can see the potential benefits very clearly, but these benefits need to be explained to a wider audience of senior decision-makers, budget holders, and the public. So, in local public services, why use predictive analytics, and how can we also be more alert and responsive to risks and challenges?
Better outcomes
All those we spoke to tended to agree the most important benefit to come from using predictive analytics is that it enables councils to deliver better outcomes. This might be through better decision-making, or from better prioritisation of resources (for example, by freeing staff from routine tasks to devote more time to the complex cases).
In practical terms predictive analytics can assist frontline staff to flag specific cases from amongst large caseloads and identify cases which are not yet in crisis but which could worsen if preventative steps are not taken. Tools to support preventative approaches are increasingly valued in healthcare, social care, homelessness, debt management and troubled families: the latter has often provided a testbed for pioneering predictive analytics. You can read more in this Government blog for the Troubled Families Programme.
Perhaps the clearest example of predictive analytics producing better outcomes is in the often-quoted example of breast cancer screening. Studies, such as this one published in The Lancet, have now found that the performance of radiologists supported by predictive software is significantly better at reading scan images than un-assisted human scan-readers. False positives (those without cancer who are told they may have cancer) and false negatives (cancers that are missed) were both reduced. This means fewer patients experiencing delays in urgent treatment, and fewer patients having the stress of misdiagnosis. A comparable example in local government would be avoiding unnecessary action by children’s services in cases where there is no need, which reduces the stress on families from unnecessary intervention, whilst enabling resources to focus on cases which do require help.
Targeting scarce resources
As councils continue to face extreme budget pressures, they face the choice between spreading their reduced resources more thinly or dealing only with the most needy cases. We have seen this in a number of areas, including homelessness and social care. The authors of The Future of Predictive Analytics in Councils (another paper we strongly recommend to readers), based on experience in Essex, argue these technologies ‘focus the allocation of scarce resources, identify adverse events and ascertain the effectiveness of tested interventions’. The paper explains how this can be achieved through more accurate risk stratification.
Decision support
Predictive analytics, as a subset of AI more generally, is still a long way from being able to judge information as effectively as a human. While predictive analytics can perform singular tasks for which it has been trained (sometimes better than a human), it cannot replace humans entirely, nor should it. More generally it is worth noting that the narratives on these kinds of technologies are often several years ahead of the reality; for example, while it has become commonplace to hear references to ‘artificial intelligence’ being used in many areas of our daily lives, there is no current working example of artificial general intelligence (a single system with wide-ranging, human-like cognitive abilities).
In practice, therefore, the benefits for the time being of predictive analytics come from being an assistive tool for human decision-makers rather than a substitute, able to far better find early evidence of systematic patterns which can be flagged as likely to lead to a negative end result. At the same time, human decision makers can understand the context outside of the immediate issue. One such example could be a software programme used to identify which domestic heating systems need replacing. A housing services engineer can look at the short-list and use the tacit knowledge and understanding of the entire situation, which may not yet be reflected in any of the data eg. most boilers on the target list may need replacing but some may be in homes which are likely to be fully refurbished, allowing them to decide whether a repair should be prioritised.
In the Nesta Decision-making in the Age of the Algorithm report, the authors describe a set of principles to guide human-machine interaction. The central idea is that “for predictive analytics tools to be effective, frontline practitioners need to use them well”. They call for frontline staff to be helped and trained to use insights from digital tools alongside their own professional judgment; the authors call this combining of human and computer input ‘artificing’.
Improving responses through time critical alerts and decisions
Finally, predictive data methods, when combined with real time data feeds, create opportunities to deploy preventative help in time-critical situations.
As illustrated in the Hertfordshire case study, the system can anticipate when there may be an imminent risk of an individual experiencing a medical emergency. Sensor data from the lead up to previous medical emergencies can be captured and used to train software to identify similar patterns which indicate another emergency may be imminent. Health and care workers can then be dispatched to the individual’s home to check on the individual and take action if necessary.
It is possible to imagine the same concept being applied in other fields, to prevent individuals suffering from homelessness, serious financial trouble, or other ‘bad’ events. For example, the Government of Jersey are using predictive analytics to identify students at risk of becoming NEET (not in employment, education or training) after leaving school, using risk stratification based on indicators while they are still in education.
Risks and challenges of predictive analytics
As well as understanding the benefits, decision makers and the public also want to be assured that local government recognises the risks and challenges and understand how these can be mitigated.
Here we highlight three significant risks. Alongside these are other potential challenges which are discussed in the next section of this guide.
The risk that the software will not deliver improvement
There have been several high-profile instances of councils dropping a predictive analytics system after it failed to deliver as hoped. These cases, particularly where councils have purchased software from third-party suppliers for use in areas such as children’s services or welfare, have attracted negative media coverage in which the software is portrayed as a waste of scarce resources. We have heard from councils and the LGA themselves that this is fuelling broader caution at senior and frontline levels about the use of predictive analytics in the public sector regardless of whether the root cause of failure was poor-quality data, poor software, poor clienting or some other factor.
The next chapter of this guide offers advice for local authorities planning to purchase third party predictive software: around contractual measures of accuracy, the need for strong clienting, and the creation of in-house ‘challenger teams’ to provide benchmarks for assessing the quality of bought-in services. Generally, the challenge is to identify quickly when a model is not delivering and to stop using it, rather than continue investing in an approach which shows insufficient results.
There are also risks of unintended consequences. For example, there are long-held concerns that introducing computers into decision-making can lead to human operators becoming complacent or over-reliant on their computer support; as a computer becomes more reliable it also becomes harder for the human operator to keep paying attention. This has been dubbed the ‘control problem’. More information can be found in Algorithmic Decision‑Making and the Control Problem. As a very practical example, US author Virginia Eubanks argues in ‘Automating Inequality’ that minor errors while filling in a form can, if human decision makers defer to algorithms, have a major impact on the ability of a person to, for example, claim benefits.[1]
The ethics of using data and gaining public trust
One issue commonly raised in our action learning discussions was how to balance benefits with disbenefits. For example, do the benefits of using CCTV to gather data which enables health emergencies to be predicted outweigh the disbenefits of the intrusion of privacy? In contrast, we also heard questions about the ethics of not using a predictive model which officers know can deliver improved outcomes, and whether not using that technology can be justified.
Over the past decade, and particularly since the introduction of the General Data Protection Regulation (GDPR), the default position (although there are notable exceptions) has been for data-holding organisations to use personal data in ways which minimise the chances of individuals being identifiable. This Nesta guide on public sector data analytics has more information.
This basic minimum standard is often not enough to assure the public that local government is using data or predictive analytics in a responsible and ethical fashion. Concerns about in-built algorithm bias, and balancing the public good, require more than basic GDPR compliance and relate to the issue with our ‘digital social contract’ mentioned previously. This can take a number of forms, such as statements explaining the benefits, deliberative public discussions or citizen assemblies, or local charters like the New Zealand algorithm charter setting out how residents’ data will be used.
The ICO guidance on Explaining Decisions Made with AI is very helpful here; it breaks down six different ways of explaining computer-based decisions including explanations of ‘rationale’, of ‘responsibility’, and of ‘fairness’.
The Centre for Data Ethics five-point framework for building trust (mentioned earlier) is another useful guide to action.
The risks of in-built bias on inequalities
One of the many issues highlighted by the problems with school exam results in the summer of 2020 (when awarding bodies had to generate grades in the absence of exams) was that of bias reinforcement in computer-based decisions.
The plan was that the software would be used to predict pupils’ grades based on how pupils at the same school has done in previous years. One of the clearest examples of bias was that a high performing student from a school which had under-performed in recent years would be moderated down by the software, because pupils from that school tended not to do well. Given that poorer performing schools tend to be in areas of lower socio-economic status this basically meant that bright pupils from poor areas were down-graded because pupils from their neighbourhood had done less well in the past. The bias reinforcement effect here is obvious.
The same can happen in other use cases: female applicants to engineering jobs could be given lower weighting in automated recruitment sifting because previous successful candidates (whose data was used to train the software) tended to be male.
Tackling bias needs to start with the development of the model including the selection of training data, and thorough analysis of any existing bias which needs to be reversed. It also needs to include monitoring of the model when live, to ensure that potential bias can be dealt with before it becomes systemic. These mitigations could be achieved by involving those who are impacted or who use the model, to understand how the bias could manifest. Tackling these forms of bias should not be the sole responsibility of council data teams but should involve existing council expertise around equalities and reducing bias in decision-making more broadly.
[1] Eubanks, V. (2018). Automating Inequality: How High-tech Tools Profile, Police and Punish the Poor. St. Martin’s Press
Practical guide for data teams and decision makers
In early 2020, Shared Intelligence ran a series of action learning sets with data analysts and managers of data teams from 30 English councils who were actively working on or considering predictive analytics projects. These sessions were designed to gather insight of the issues currently faced by councils when developing predictive tools and to support progress by enabling data analysts to share and overcome challenges and barriers. This section is a guide for others developing and using predictive analytics based on these discussions.
This section is structured around the practical issues data analysts are likely to encounter as they identify local public service challenges that predictive analytics could solve and move to design, build and deploy solutions.
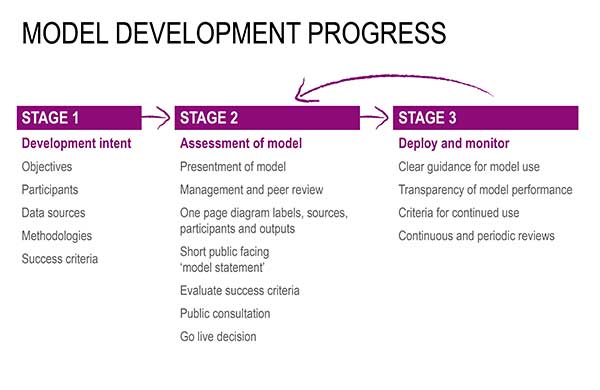
A model development process for delivering predictive models
As part of the action learning set sessions we invited a data scientist with experience of predictive analytics in commercial settings (including the finance and energy sectors) to contribute advice and an external perspective to the action learning sessions and help with the development of this guide.
He also created the following schematic for planning the development of new predictive analytics projects in the public sector. This formalises what we heard from action learning participants, and also draws on the way these technologies are approached in other sectors. It is set out in three stages which we have used to organise this guide section:
- development intent
- assessment of the model
- deployment and monitoring – and loop back to assessment.
Developing the intent – identifying a problem predictive analytics might solve
This section is about the stage at which a problem is identified by a data team or a service delivery team, which a predictive model could potentially solve. The most important question is ‘what problem are you trying to solve and what could predictive analytics do to solve it?’.
Approach
It is important to develop a narrative or business case setting out the problem and appraising whether predictive analytics has potential to add value and take the proposal to those senior managers whose support is needed most to take the project forward.
Project leaders should check early on what problems are faced by staff and users that could be solved by predictive technology, which will inform decisions about whether a project adds value and is justified. Ideally this should include first-hand user or public perspectives.
There should be an initial appraisal of what data is available; is it consolidated or fragmented, is it likely to be fit for purpose for developing a predictive model?
There should be close discussion with frontline staff to find out whether they see predictive analytics as a value-adding approach (or indeed whether they are aware of this type of technology). More information can be found in the Government Service Manual on user research.
Issues that could emerge
Frontline staff and senior managers may have concerns which, if not addressed, could slow the project or become barriers. To address this, data analysts should engage with frontline colleagues in the early planning stages to understand what they want from the project. It also helps when data teams can deliver internal communications and training to develop better understanding of predictive analytics – which helps both in broader understanding and also in understanding the importance of data quality.
Some predictive analytics projects can become re-framed as savings-driven rather than improvement-driven and this is rarely helpful. Projects that become framed purely around savings often run into difficulties around staff and public perception, expectations, how success is measured, and the relationship between staff and the technology. This can be avoided at all stages from business case to implementation by focusing on how the technology can assist human decision-makers to obtain better outcomes.
To build trust and show proof of concept it can help if the first implementations of predictive analytics within an organisation addresses challenges where there are clear user benefits, but which do not involve critical or contentious services. Start simple to prove the value of predictive analytics and to build support, before scaling up to greater complexity. Projects with potential greater benefits, involving new technologies in sensitive or critical areas of local services (eg care, safety, protection, assessment of entitlement) will always need more justification and evidence of benefits up front, and will face more scrutiny around risk mitigation.
Assessing potential models and approaches
This section focusses on two main questions; (1) what kind of approach will be viable given the data currently available, and (2) how much should the council attempt to build in-house versus purchase from a third party – the criteria for this second decision must reflect the specific outcomes a council is trying to achieve with predictive analytics which might differ from other IT- sourcing decisions.
Approach
Project leaders should make a detailed appraisal of the quality of existing data using the Government’s guidance on the quality of data needed for AI-type applications which identifies nine essential factors: accuracy, completeness, uniqueness, timeliness, validity, sufficiency, relevancy, representativeness and consistency. This will help determine what is possible with the data available and the viability of a data-reliant project.
An important decision – which budget holders will need to take - is whether the council should buy-in a third-party product or develop the project in-house. There are many factors to consider but in terms of process this should be a joint decision involving the data team, and frontline teams running the services it will apply to, in order for sound and transparent choices to be made.
Where a third-party product is used, data teams should work (at pre-contract stage) with the prospective client-side manager:
- set clear requirements around outcomes, including accuracy thresholds, and
- build in requirements for data teams and frontline staff to be trained by the provider to ensure they understand product functionality and how to maintain it and maximise benefits.
Where a council wants to understand more about the costs and benefits of in-house versus third-party provision, this can be achieved by developing an in-house challenger model alongside the third-party product to provide harder comparative metrics eg on accuracy, relative costs, and benefits.
Colleagues in corporate IT should be approached to ensure they understand the project and what support will be needed that they can assist with. These include basic enablers eg access to specialist software, or introducing new hardware to the council network, and strategic enablers eg ‘infrastructure, both hard and soft, such as high-speed broadband and good data storage...’ The discussion paper ‘Datavores of Local Government’ by Nesta has more information.
In terms of data handling, there is often a case for moving away from MS Excel to more sophisticated tools. However, MS Excel may have advantages over more sophisticated systems when the capability of frontline staff is taken into account; where data-gathering relies upon frontline staff it may be better to use software they are proficient with and have access to, albeit in a disciplined manner and following good data protocols and conventions.
Issues that could emerge
Data teams may discover a commercial product has been purchased by another part of the council which does not suit the council’s long-term needs or align with the council-wide approach to data. To reduce this risk, data teams should ensure they are consulted about purchases of any data-related products or services.
Availability of essential data analysis skills is a common challenge and many data analysts are self-taught when it comes to predictive analytics. Issues around skills can be overcome by regular sharing of learning within data teams, co-option of individuals with specific skills, and outcome focused training plans. The What Works Centre for Children’s Social Care has also called for more networking of data practitioners nationally to create a stronger sense of common professional culture.
Deploying and monitoring
This section highlights the need to build support and educate colleagues at all levels. Building a model is only the first stage towards an operational approach. It is essential to work with those frontline practitioners who the model is intended to help, to get early feedback and to ensure predictive analytics integrates into their working practice. Once the model is deployed and begins to be refined, the refinement process is another route to engage frontline staff and increase their understanding and confidence with the technology.
Approach
Deployment of a predictive analytics project should begin in close collaboration with staff and managers from the service to which it relates. Collaboration with the service from planning stage onwards should continue into implementation, including working closely with frontline staff (not just managers) to gather further insight into what is needed, and to build systems around their practice and working methods. This will make it easier for frontline staff to learn how predictive analytics can be combined with their own professional judgement and knowledge, also known as ‘artificing’. The Nesta report Decision-making in the Age of the Algorithm outlines more information.
Where projects require new forms of data-sharing, agreement will be needed from the council’s data protection officer and senior level managers in the service delivery teams concerned. Where this falls across organisations boundaries (eg. between councils and health, or in two-tier areas), data sharing will probably need to be designed as a two-way flow not just from the service to the ‘centre’ but also the other way. However, inter-organisational sharing of data can also lead to better relationships on other issues.
Initial prototypes or proof of concept models not only lessen the scale of data sharing required for the design-phase, but can also help make the case for more extensive (and difficult to agree) data-sharing as a model is scaled up later on. Partnerships with data-focused institutions (eg data observatories, academic institutions) can be beneficial and draw on their experience, which can shortcut learning and build confidence and trust.
Issues that could emerge
Data sharing agreements between authorities and other public organisations or with third-party organisations can be incredibly difficult to secure; data sharing between the different tiers of local government seems especially time-consuming. Reliable real-time or near-time linking of data, both within and between authorities and external organisations, can also be difficult to achieve. To address this requires high level leadership direction and statement of intent so that everyone involved understands that solutions must be found. National efforts have been made to accelerate data sharing between public bodies, the most notable being Nesta’s ‘Offices of Data Analytics’ programme. This aims to provide ‘a model for multiple organisations to join up, analyse and act upon data sourced from multiple public sector bodies to improve services and make better decisions’. Many authorities such as Essex, Greater Manchester and North Yorkshire have set up local offices of data analytics. Essex, for example, has demonstrated the county council, districts and third parties, such as universities, are able to work together to share data and build capabilities together, for example, with the police to reduce vulnerability.
Many data analysts encounter versions of ‘Excel hell’ once they implement projects that require data from across their authority (eg poor basic data hygiene, multiple legacy datasets, missing data). This can be addressed by upskilling (eg through teach-ins or internal comms) around what ‘good’ data can be used for, and by raising awareness of essential data standards and best practice protocols. The reliance on data for COVID-19 shielding activities has led to major improvements in council data hygiene and these changes provide a chance to make permanent improvements in data practice, for example, using the Unique Property Reference Number (UPRN) protocol for internal case management systems to allow more accurate linking of data. .
Where predictive analytics projects are implemented without close engagement with frontline staff, those staff might be cautious about the technology and/or the technology may not fit well with frontline workflows. This can be addressed by close engagement with frontline staff during implementation on broad principles and on technical detail such as trigger levels for flags and alerts. This could be with all staff or alternatively a small number of frontline ‘champions’ who possess the greatest knowledge and interest. This may also have the additional benefit of them understanding the value of improving the quality of their data.
Skills development and peer learning
Some of those working in local government on predictive analytics (or managing teams who do) have formal training as data scientists, but many are self-taught having worked previously in fields such as performance reporting. This means that many have not come through the mathematics and statistics training routes more common among data scientists. This in turn means training and peer learning is of great importance among those delivering, managing, or clienting predictive analytics projects. This can be addressed by:
- providing opportunities to share learning and new approaches across local government and for those with more experience to showcase progress and teach to others
- seeking opportunities to learn and consolidate skills, either through data-focused apprenticeships or through placements with external companies or organisations
- bringing in staff with data-science skills to work within councils, for example, for specific capabilities or to fill a time-sensitive vacancy – and to set-up these arrangements so there is knowledge transfer
- articulating training goals in terms of improved service outcomes, to enable managers to allocate time, budget, and resources.
There is also potential for extending the established model of local government peer review to focus on predictive analytics and related data technology. This seems important given this is an emerging field in local public services and staff often lack access to support and challenge from within their own authority. It also reflects the fact that practice is in a rapid phase of development. The existing local government peer review model could be combined with other models such as the framework for the peer review of predictive models produced by the UN’s Office for the Coordination of Humanitarian Affairs.
Tracking the maturity of organisational progress on data
It can be difficult for councils to form an objective view of how advanced they are in the use of predictive analytics and data analytics more generally. This is important as it helps in framing internal discussions to know whether ‘this council is a pioneer doing things few others have done’ or ‘this council is behind many others so there are already many examples to draw from’. There are two existing data maturity frameworks which may help a council to understand their own level of data maturity, including the skills of the data team and the culture of the organisation:
- The Social Sector Data Maturity Framework was developed as part of the Data Evolution Project funded by Nesta and other UK innovation funders. It provides a useful framework for measuring and tracking how organisations build their data capacity.
- The LGA, in partnership with Nesta and Porism, has developed a Data Maturity Self-assessment Tool specifically for local government, which asks councils to critically evaluate their own progress in several specific areas.
Both these frameworks provide an opportunity for data teams to identify areas where progress is limited, and proactively take steps to address this. These should therefore be used for any council which wants to determine where they currently stand in the use of predictive analytics.
While currently a prototype, the LGA’s Data Maturity Tool was released in 2018 and is an established part of the LGA’s offer. The Social Sector Data Maturity Framework was released in 2017, after being developed by Data Orchard and DataKind UK based on surveys and interviews. This framework is suggested by Nesta as a tool to help organisations get more from their data.
Addressing ethical issues around use of predictive analytics
There is often concern over the approach councils take to ensure there is effective oversight of ethical issues relating to predictive analytics. A significant amount of formal guidance has been produced by the Government which addresses specific ethical concerns in detail, which councils should follow, which set out established principles on public services, data, and ethics. This includes:
- for advice on ethical considerations in building a model, including mitigating the risk of a model causing unintentional harm, the Government’s Understanding Artificial Intelligence Ethics and Safety guidance establishes a number of steps to follow
- for using data appropriately and responsibly when planning, implementing, and evaluating a new policy or service, or while considering the ethics of a model, The Data Ethics Framework is the Government’s official guidance for public sector organisations
- for sharing and publishing data, the Data Standards Authority’s Metadata Standards provides an established method and standard for councils to carry this out in an ethically sound way
- for developing public trust in the use of council held data, the Centre for Data Ethics and Innovation has published a widely recognised framework for building trust with the public as part of their Addressing Trust in Public Sector Data Use guidance, which is based around five questions about ‘value’, ‘security’, ‘accountability’, ‘transparency’, and ‘control’.
As a minimum, those who follow the guidance described above will:
- Have clear lines of accountability around the use of data including data quality, data regulations, and the ethical use of data – who is responsible for what and where does the buck stop?
- The establishment of a formal board or group of senior managers who can advise and hold services to account around the key questions that the Centre for Data Ethics and Innovation advise should always be asked:
- value – who benefits and who takes on risk?
- security – what security measures are in place?
- accountability – who is responsible for decisions?
- transparency – is the rationale an operation open to public scrutiny?
- control – what role do individuals have in the decision to share data about them?
- Have open and honest discussions with residents and the wider public, particularly those whose data may be used to develop predictive analytics.
- Find routine ways to ensure the council’s data use policies are communicated in clear and transparent ways across all forms of communication.
Finally, it will be important to ensure that learning from the development of predictive analytics is shared between authorities and used to support others at earlier stages of development.